Multimodal Learning for Facial Expression Recognition
Wei Zhang1, Youmei Zhang1, Lin Ma2, Jingwei Guan2, and Shijie Gong1
1School of Control Science and Engineering, Shandong University, Jinan, China
2Huawei Noah's Ark Lab, Hong Kong
Wei Zhang1, Youmei Zhang1, Lin Ma2, Jingwei Guan2, and Shijie Gong1
1School of Control Science and Engineering, Shandong University, Jinan, China
2Huawei Noah's Ark Lab, Hong Kong
In this paper, multimodal learning for facial expression recognition(FER) is proposed. The multimodal learning method makes the first attempt to learn the joint representation by considering the texture and landmark modality of facial images, which are complementary with each other. In order to learn the representation of each modality and the correlation and interaction between different modalities, the structured regularization(SR) is employed to enforce and learn the modality-specific sparsity and density of each modality, respectively. By introducing SR,the comprehensiveness of the facial expression is fully taken into consideration, which can not only handle the subtle expression but also perform robustly to different input of facial images. With the proposed multimodal learning network, thejoint representation learning from multimodal inputs will be more suitable for FER.
The contributions of this work:
The databases contain both texture and landmark modalities for each facial image. These two modalities reflect different properties of the facial expression, which should be considered together for FER. The texture and landmark modalities of the facial image will be first processed, respectively, before being fed into the multimodal FER system.
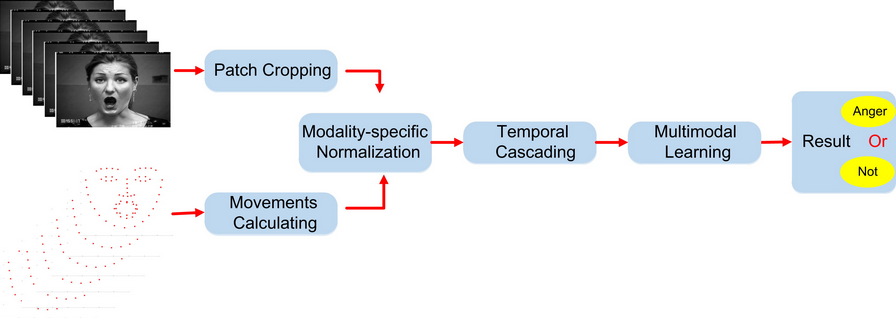
Fig. 1. The structure of our approach
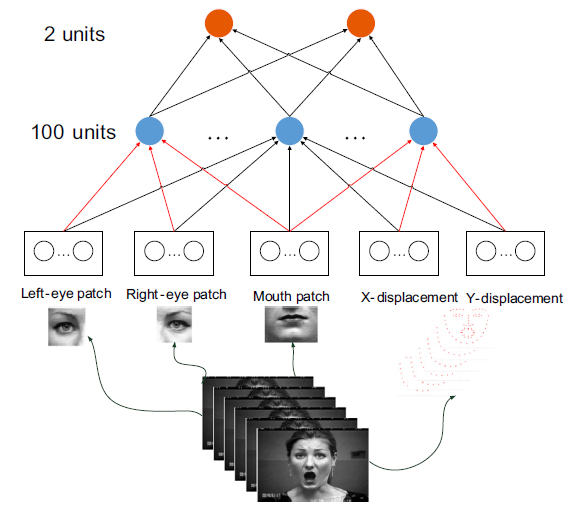
Fig. 2. The structure of the network
Multilodal FER:
The proposed learning architecture is illustrated in Fig. 2, which takes different numbers and types of modalities as inputs. The output will be the joint representation, which not only considers each modality property but also accounts for the interactions of different modalities.
For the texture modality, the image patches are extracted around eyes and mouth from one frame, which contain the most pivotal facial features related to expressions; For the landmark modality, we calculate the different value between current frame and previous one in X and Y direction as the movements of landmarks.
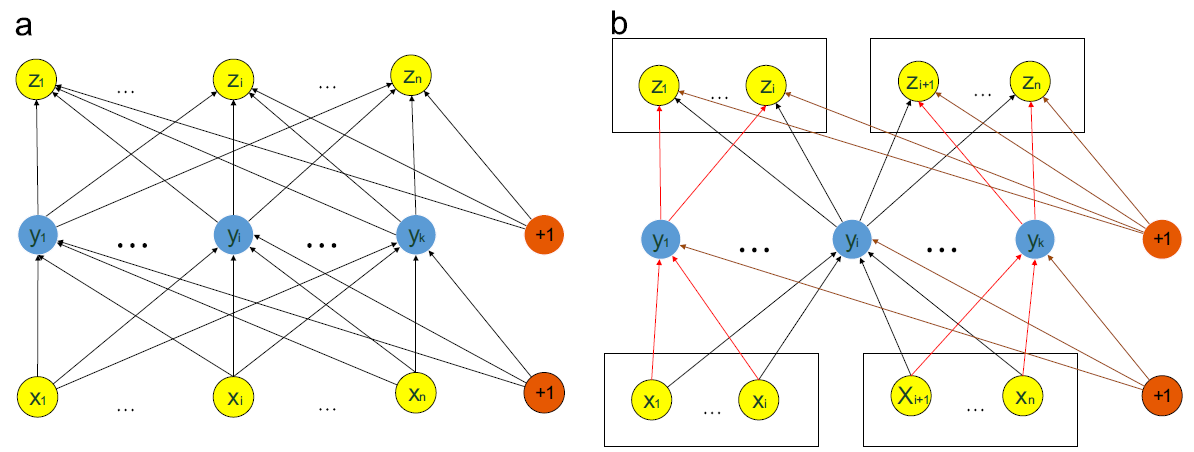
Fig.3. The structure of AE without SR(a) and with(b) SR
The network is pre-trained by auto-encoder(AE), considering each modality property and the interactions of different modalities, structured regularization(SR) is attached to AE. The structure of AE without and with SR is shown in Fig.3.
Comparison to prior study on CK+ database(First 6 frames)
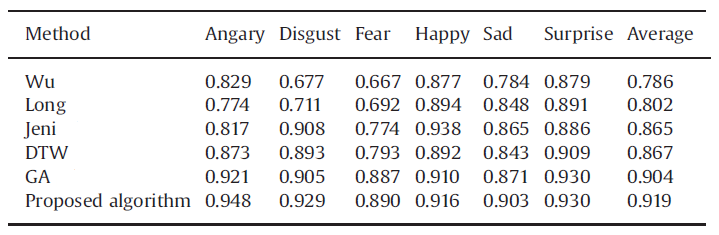
Comparison to prior study on CK+ database(First-Last)
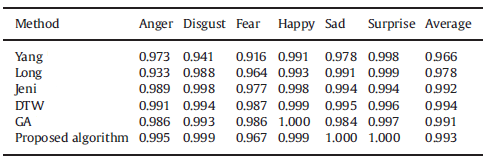
Comparison of the algorithms with and without AE

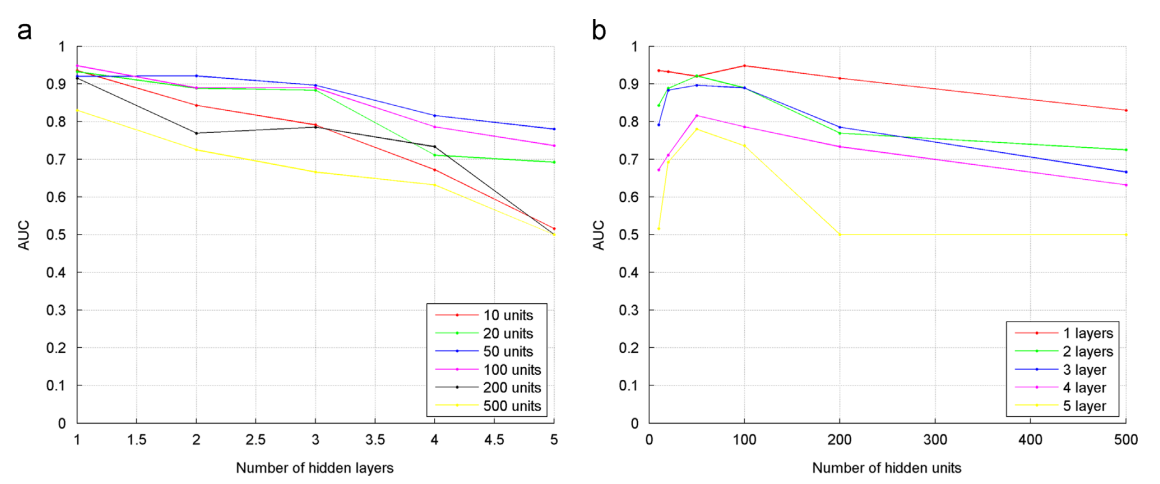
The recognition result with respect to the number of (a) hidden layers, (b) hidden units
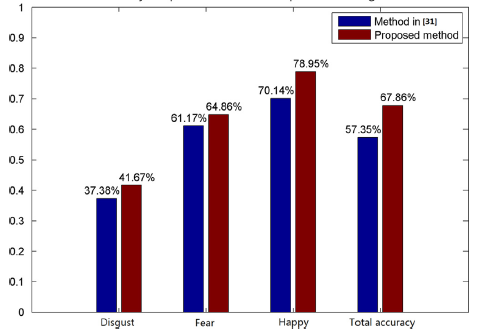
Experimental results on spontaneous facial expression database
Wu et al. Long et al. Jeni et al. Lorincz et al. Yang et al. Wang et al. He et al.
Update: Apr. 27, 2016
